In statistics, we often need a single value to represent an entire dataset. This "typical" value is known as a Measure of Central Tendency. These summary statistics provide a central point around which data observations tend to cluster. Whether you are analysing exam results or house prices, understanding the mean, median, and mode is essential for interpreting the story behind the numbers.










Theory
There are three primary ways to measure the "centre" of a dataset. Each has its own strengths depending on the type of data provided.
1. The Arithmetic Mean
The mean is the most common average. It is calculated by summing all the observations and dividing by the total number of values.
The formula for the mean is:
- Best for: Data that is spread symmetrically without extreme outliers.
- Weakness: Highly sensitive to extreme values (outliers).
2. The Median
The median is the middle value of a dataset when the numbers are arranged in order of size.
- If n is odd, the median is the middle number at position:
- If n is even, the median is the average of the two middle numbers.
- Best for: Skewed data (e.g., salaries or house prices) as it ignores outliers.
3. The Mode
The mode is the value that appears most frequently in a dataset.
- Unimodal: One mode.
- Bimodal: Two modes.
- No Mode: If all values appear with the same frequency.
- Best for: Categorical data (e.g., most popular car colour).
Summary of Measures
The following table compares when to use each measure:
| Measure | Type of Data | Sensitivity to Outliers |
|---|---|---|
| Mean | Interval/Ratio (Numerical) | High |
| Median | Ordinal/Numerical | Low |
| Mode | Nominal (Categorical) | None |
Measures of Position (Quartiles)
Beyond the center, we often divide data into four equal parts called Quartiles.
- Lower Quartile (Q1): The 25th percentile.
- Median (Q2): The 50th percentile.
- Upper Quartile (Q3): The 75th percentile.
Worked Example
A student records their test scores: 12, 15, 12, 18, and 23. Calculate the mean, median, and mode.
1. Calculate the Mean - Sum the values: 12 + 15 + 12 + 18 + 23 = 80, divide by the count (5):
2. Calculate the Median - First, arrange in ascending order: 12, 12, 15, 18, 23. The middle value (3rd position) is 15.
3. Calculate the Mode - Identify the most frequent value: 12 appears twice, others appear once. The mode is 12.
Practice Questions & Solutions
Find the mean of the following dataset:
5, 10, 15, 20, 25, 30
Sum of the values: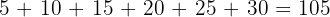
Number of values: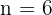
Calculation:
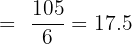
Determine the median of this dataset:
7, 3, 11, 2, 9, 15
Arrange in order:
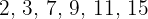
Identify the two middle numbers:
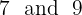
Find the average of the middle numbers:
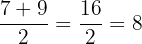
Identify the mode(s) for the following set of data:
Blue, Red, Blue, Green, Yellow, Red, Blue
Count the frequency of each category:
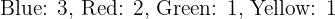
The most frequent value:
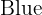
Calculate the Lower Quartile (Q1) for the ordered dataset:
2, 5, 8, 10, 12, 15, 20
Use the formula for the position of Q1:
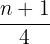
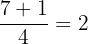
The value at the second position is:

A dataset has a mean of 10 for 4 values. If a 5th value of 20 is added, what is the new mean?
Find the original sum:
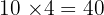
Add the new value:
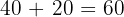
Divide by the new count:
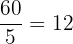
Summarise with AI:
Did you like this article? Rate it!


